7月7日,由世界人工智能大会(WAIC)主办的首届全球算法最佳实践典范大赛(BPAA)总决赛暨算法峰会在沪举办。作为全球前沿算法应用型赛事,BPAA面向来自中国、北美、欧洲、亚太赛区的国际参赛团队,从七大区域、五大领域角逐出优秀顶尖算法项目,打造全球算法高地。
第四范式副总裁、主任科学家涂威威作为大赛主评委出席此次峰会,并发表了题为「数据驱动的决策智能:环境学习与强化学习」的主题演讲,详细阐述了如何通过两大技术构建企业AI决策能力并落地应用。

AI加持 智能决策转向“人机协同”
众所周知,企业经营离不开决策,决策的质量决定了企业管理水平,进而深刻影响企业发展。此前,企业通过构建“以人为中心”的分层决策体系来运作,例如高层决定公司重要战略,业务负责人决定业务发展方向等。
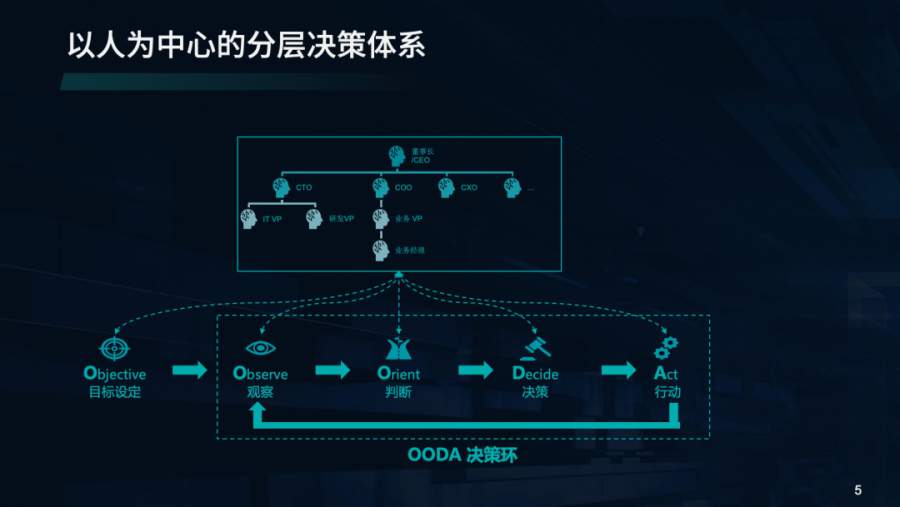
决策过程可参考著名的OODA Loop决策周期理论,由“观察(Observe)- 判断(Orient)- 决策(Decide)- 行动(Act)”四个环节组成的相互关联、相互重叠的循环周期。“观察”,即需要企业全面观察,为决策提供充足的信息依据;“判断”,基于观察精准判断所处现状及未来发展,为决策提供参考结论;“决策”是指制定较优的决策方案,为整个决策流程走好关键一步;“行动”则是基于前三步的成果采取相应措施。在整个决策周期中,能否理想的完成观察、判断及决策环节,决定了业务决策的整体质量和效果。
然而,企业依靠人做决策的过程中面临多重挑战。人的计算能力是有限的,只能通过抓大放小的方式作出有限的判断和决策,且庞大的企业组织带来的决策效率等问题,难以对瞬息万变的商业环境快速反应。
因此,企业未来的决策体系将由“以人为中心”走向“人机协同”,借助AI不知疲倦、面面俱到的优势,新的决策体系可以在海量的数据中全面学习,并在分秒间做出有效决策,提升企业决策效率,打通组织决策闭环。
“人机协同”的体系主要分为两种模式:计算机辅助决策与计算机自主决策。
环境学习 让计算机辅助决策变得“有理有据”
此前,辅助决策主要是借助数字孪生、仿真模拟等技术让机器来辅助人做决策。当前的数字孪生是利用传感器、业务系统收集的数据,打造一个反映物理世界全生命周期的数字化系统。其核心价值在于能帮助企业更好的观察业务发展,即解决了OODA的第一步。
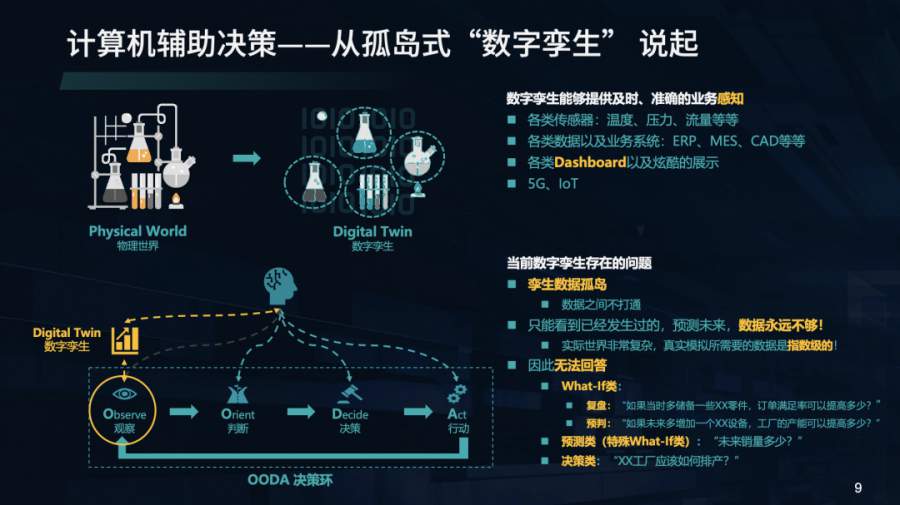
然而,大多数数字孪生系统只解决了观察的问题,各个业务节点的数据采集往往是孤立的,因此,数据之间互不相通,造成了孪生数据孤岛。同时,由于实际业务决策非常复杂,如果要覆盖所有可能的业务状况与决策手段,所需要的数据是指数级的,当前采集的数据量级远不足以支撑所有决策情况的全覆盖,甚至可以说是永远不够的。此外,更为关键的是,现有的数字孪生无法解决以下3类辅助决策的关键问题,从而限制了数字孪生的应用发展。
1.What – If类问题
复盘:如果当时多储备一些XX零件,订单满足率可以提高多少?
预测:如果未来多增加一个XX设备,工厂的产能可以提高多少?
2.预测类问题(一种特殊的What-If类问题)
未来销量多少?
3.决策类问题
如何排产?
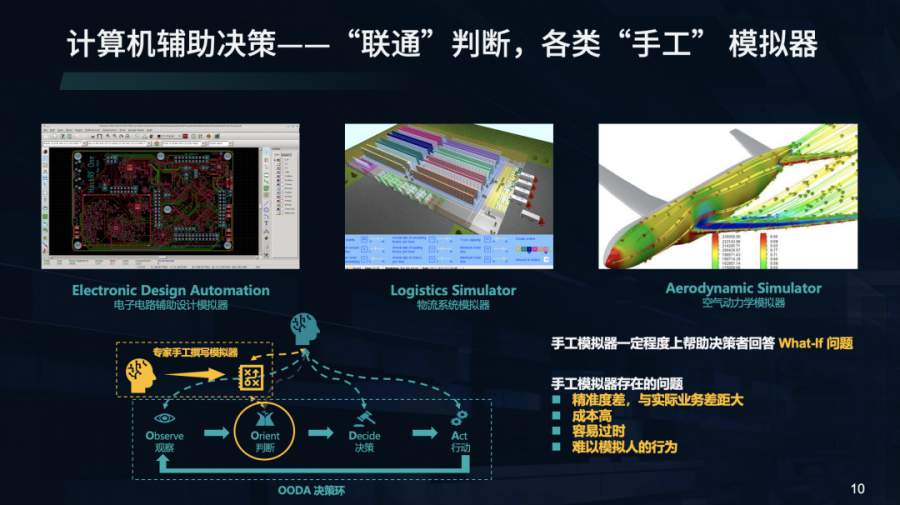
另一种方式是通过手工模拟器进行仿真模拟去辅助人做判断,即OODA第二步。它可以一定程度上回答What – If类问题,应用在电路设计、物流系统、空气动力学研究等领域。但是,由于其主要依托于人的经验和知识,实际业务千差万别,专家很难面面俱到,只能抓大放小,因此也存在精准度低、成本高、难以应对环境快速变化、难以模拟人的行为等问题。
对此,第四范式将OODA中的“观察”、“判断”进行结合,融合了数据驱动的机器学习与专家知识驱动的机理模型,提出了新的计算机辅助决策技术「环境学习」,以此构成接近真实世界的虚拟环境,很好的弥补了数字孪生和模拟仿真技术缺陷。
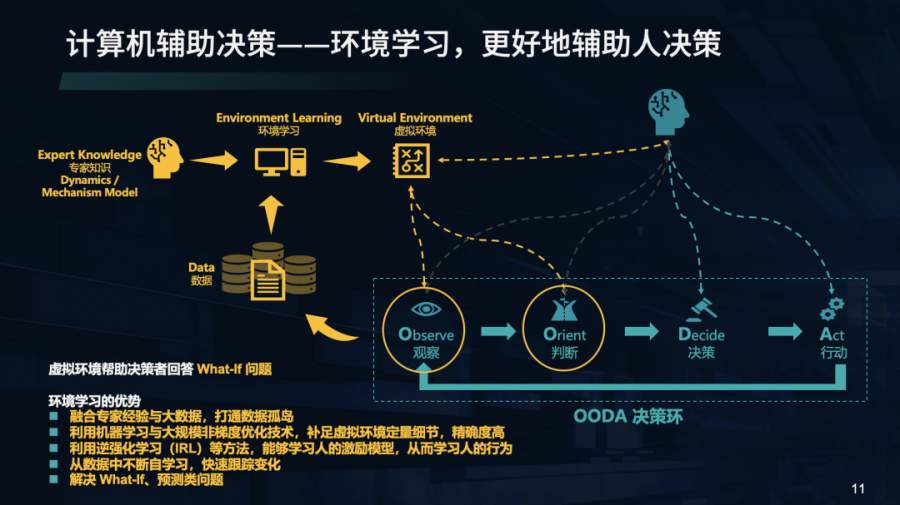
在数据方面,针对专家有限决策以及实际业务数据量不足以预测的问题,环境学习融合了专家经验与大数据,打通数据孤岛。同时,针对专家无法定量的分析问题,环境学习可以从现有的数据中学习,借助机器学习以及大规模非梯度优化技术,补足虚拟环境定量细节且精确度高,并通过机器不断的自学习,快速迭代,对环境变化做出及时反应,以更好地解决 What-If、预测类问题。同时,环境学习还会借助如逆强化学习等技术手段,更好地学习决策环境中人的激励模型,从而提升对决策环境中人的行为预测泛化能力。
由于综合了专家知识、机理模型和数据驱动的机器学习能力,「环境学习」能够构建更为精准的虚拟环境,因此可以为人的决策提供更加精准的预判,定量推演在不同决策情况下的业务发展,从而使得人做决策不再“拍脑袋”,变得有据可依。
此前,为了更好地辅助疫情防控,第四范式率先将「环境学习」技术应用在疫情防控系统中,为追踪传播路径、筛查高危人群、推演疫情发展等疫情防控关键环节提供参考。相比经典的传染病SEIR模型,基于「环境学习」的方案推演误差降低超过90%。
环境学习+强化学习 加速计算机自主决策广泛应用
「环境学习」解决了“观察”、“ 判断”,通过学习得到的虚拟环境,可以辅助人进行更好地决策,但仍然未实现机器的自主决策,即便有了环境学习,人做决策的时候往往也很难做到精准与实时。
首先,实际决策场景中影响因素复杂且繁多;其次,实际业务关注长期回报,需要连续决策而非单次决策,而且决策效果往往延迟体现;最后,实际业务需要精细化决策,决策量庞大,部分业务还需要实时决策(比如毫秒级响应)。诸如以上原因,让现有的基于人和传统运筹学的决策优化方式,很难有效解决实际业务中的大规模连续实时精准决策问题。
业界较为常见的做法,是利用「强化学习」技术,通过决策体与决策环境不断的交互,形成反馈,从而在各种试错中找到最大的收益方式。
相比于人和运筹学,强化学习更为适合解决复杂实际决策问题。首先,得益于深度学习技术的发展,深度强化学习技术借助深度学习,使得决策策略可以融合复杂场景的大量因素;其次,结合功劳分配(Credit Assignment),可考虑连续决策的长期影响;同时可以依靠计算机强大的计算能力,提供大量精细化决策,并依靠分层强化学习技术,实现不同决策层级的自主决策。不同于传统运筹学技术依靠漫长复杂求解过程来响应实际决策需求,强化学习训练得到的策略往往具有极强的实时响应能力。
然而,强化学习采用试错方式学习,在实际应用中,强化学习的学习过程需要与真实环境有大量的交互,真实环境中的试错代价往往是极其高昂的(比如无人驾驶、产线调整等),且是不可逆的(比如新冠疫情防疫中,若尝试封城那就无法获知不封城的结果,若不封城就无法获知封城的结果)。由于当前强化学习技术极低的样本利用效率,企业难以支撑强化学习大规模的试错成本与代价。
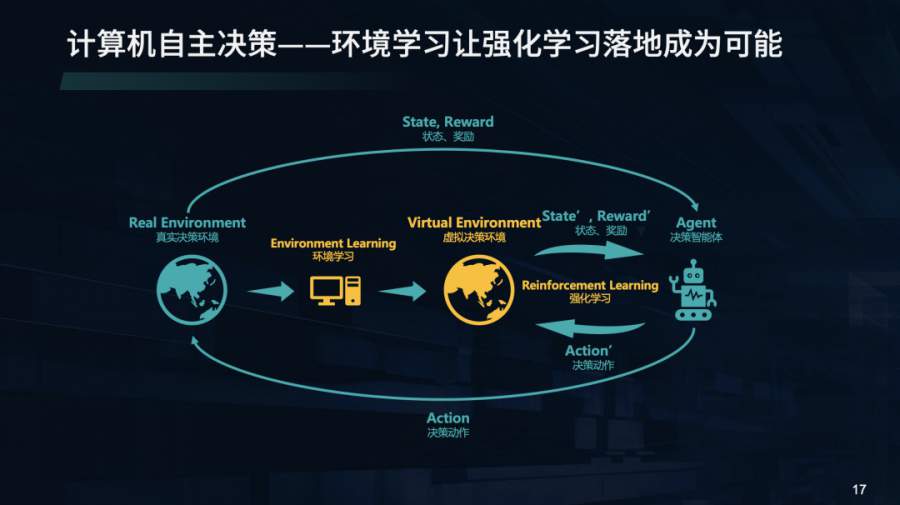
「环境学习」加速了「强化学习」落地应用,通过「环境学习」构建的虚拟环境可以帮助强化学习做低成本试错和策略迭代,「环境学习」和「强化学习」的融合方案构建了机器的自主决策能力,从而打通了“观察”、“ 判断”、“ 决策”、“行动”四大决策环节,AI直接解决决策类问题。
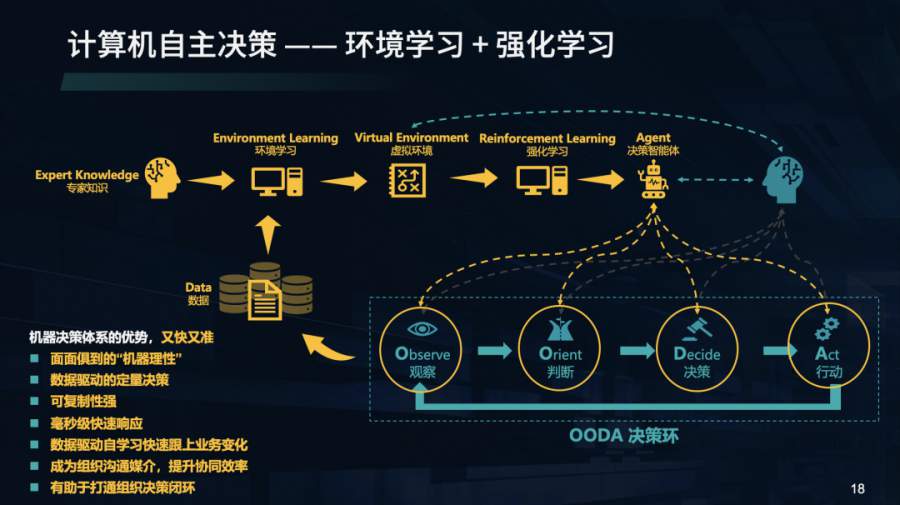
该方案能够充分发挥机器的优势,实现数据驱动的定量决策,在实时决策的同时,快速跟上业务变化,做到面面俱到的“机器理性”。同时也可以成为组织沟通媒介,提升协同效率,有助于打通组织决策闭环。
目前,第四范式基于「环境学习」与「强化学习」的方案已广泛应用于产品研发、制造派工排产、博弈类、推荐系统与市场营销等场景中,其中帮助某零售连锁企业实现了精准销量预测及智能补货,供应链成本相较于基线降低20%以上,为供应链补货、调拨、进销存计划提供了科学参考依据。
免责声明:凡本网注明 “来源:XXX(非经济参考网)” 的作品,均转载自其它媒体,转载目的在于传递更多信息,并不代表本网赞同其观点和对其真实性负责。



